
探新AI-跟AI聊了一小時,它真的會共情么?不!它腦子里全是“Token、Token、Token”
深夜 emo 了,打開大模型,噼里啪啦打了五百字,把從小到大的委屈全倒給它。它回復你:“我理解你的感受,這確實很不容易。”
你心里一暖 —— 哇,它懂我。
別感動了。
我?guī)湍惴g一下它腦子里真正在想什么:“第 1 個 Token、第 2 個 Token、…… 第500 個 —— 好的,現(xiàn)在該預測第 501 個 Token 了。”是不是瞬間下頭?
今天我們就來扒一扒,這個讓 AI “假裝共情” 的幕后黑手 ——Token。
Token 到底是啥?往小了說,就是 AI 的 “一口量”
我們看到 “蘋果” 兩個字,大腦直接反應:紅色的、圓圓的、能吃、嘎嘣脆。
大模型看 “蘋果” 呢?它看到的是兩個 Token:[24522] 和 [18432]—— 對,就是一串數(shù)字。
Token 可以粗暴地理解為:AI 能消化掉的最小的文字單位。有人把它翻譯成 “詞元” 或者 “標記”,中文里,一個字基本上就是一個 Token。“我愛你”—— 三個 Token。英文里不一樣。“apple” 是一個 Token,“watermelon” 可能被切成 “water” 和 “melon”兩個 Token。
所以你看,AI 認字的方式跟人完全不一樣。

Token 怎么 “切”?AI 有個秘密小本本
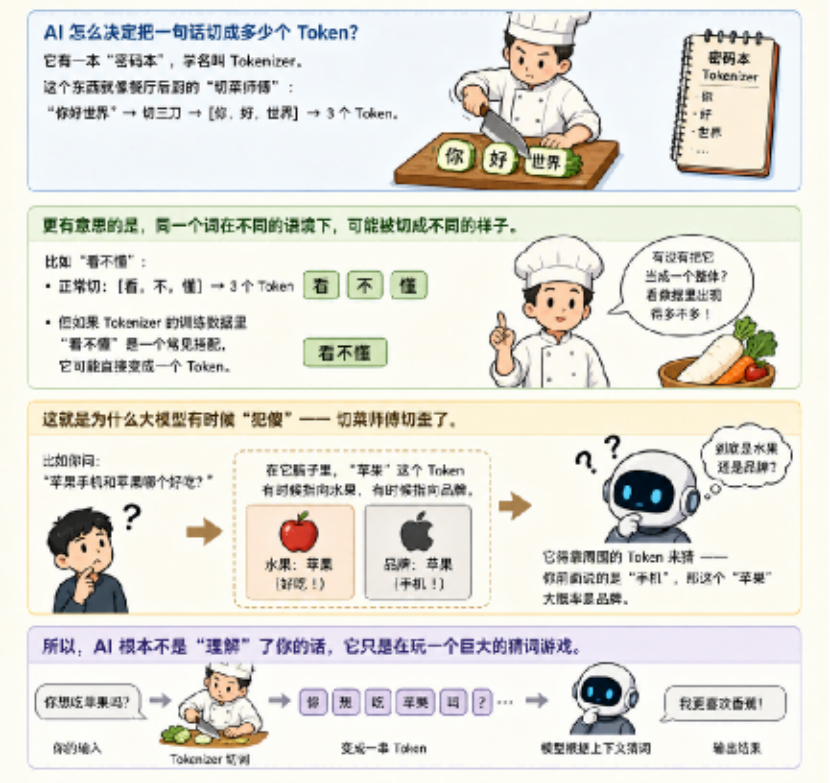
AI 怎么決定把一句話切成多少個 Token?
它有一本 “密碼本”,學名叫 Tokenizer。這個東西就像餐廳后廚的 “切菜師傅”:“你好世界” → 切三刀 → [你,好,世界] → 3 個 Token。
更有意思的是,同一個詞在不同的語境下,可能被切成不同的樣子。
比如 “看不懂”:正常切:[看,不,懂] → 3 個 Token,但如果 Tokenizer 的訓練數(shù)據(jù)里 “看不懂” 是一個常見搭配,它可能直接變成一個 Token。
這就是為什么大模型有時候 “犯傻”—— 切菜師傅切歪了。
比如你問:“蘋果手機和蘋果哪個好吃?”AI 可能會懵。因為在它腦子里,“蘋果” 這個 Token 有時候指向水果,有時候指向品牌。它得靠周圍的 Token 來猜 —— 你前面說的是 “手機”,那這個 “蘋果” 大概率是品牌。
所以,AI 根本不是 “理解” 了你的話,它只是在玩一個巨大的猜詞游戲。
Token 是大模型的 “生命線” 和 “緊箍咒”
你用 大模型?的時候,是按 Token 收費的。
輸入 Token:便宜一點
輸出 Token:貴一點
你的一篇兩千字的文章,大概 2500 個 Token,差不多人民幣一毛多。聽起來不貴是吧?但大模型每天要處理幾十億次請求,這個賬單是天文數(shù)字。所以免費的大模型有字數(shù)限制、速度限制 —— 不是它不想快,是Token太貴了。
你的每一次 “你好”,在它眼里都是:1 個 Token 到賬。
為什么說 “大模型不懂你”?
回到開頭的那個問題。
AI 真的能共情嗎?
不能。
它只是在你的五百字里,看到了五百個 Token。然后根據(jù)這些 Token 的排列組合,預測出最有可能的下一個 Token——“我理解你的感受”。
這不是共情,這是概率。大模型的 “閱讀理解”,本質(zhì)上就是 Token 的排列組合。它不知道 “難過” 是什么意思,但它的訓練數(shù)據(jù)里有 幾億次 “當用戶說難過,后面通常會接安慰的話”。于是它就那么回了。
知道了 Token 的秘密,你再跟 AI 聊天的時候,可以做兩件事:
- 把話說 “碎” 一點
因為 Tokenizer 切詞的邏輯有時候很蠢。如果你發(fā)現(xiàn) AI 答非所問,試試把長句子拆成短句子。就像跟外國人說話,語速慢一點、單詞簡單一點。
- 別對 AI 投入感情
它真的不是懂你。
它只是 —— 在 Token 的海洋里,為你預測了下一個最溫暖的詞。
下次再跟 大模型 聊到深夜,看到它說出那句 “我理解你” 的時候 ——你可以在心里默默翻譯一下:“第 1 個 Token、第 2 個 Token…。”
它是大模型世界的 “最小積木”,是大模型的 “金錢”。
它讓 AI 變聰明,也讓 AI 顯得蠢。
但最重要的是,它提醒我們一件事:
AI 沒有靈魂。它只是一臺極其擅長排列組合的概率機器。
至于 “靈魂” 這東西 —— 還是留給人類自己吧。
