
探新AI-你以為是夜宵的小龍蝦,其實是革命的技術(shù)
先問你一個問題。
你手機(jī)里要是能跑 GPT-4,你愿意嗎?
—— 如果代價是充一次電只能用 7 分鐘。
這就是大模型最頭疼的問題:太能吃了。吃的不是飯,是電。
你跟 ChatGPT 聊個天,一次對話的耗電量,是傳統(tǒng)搜索引擎的 30 到 40 倍。
為什么這么費電?
因為現(xiàn)在的大模型有個 “死腦筋”:不管問題難易,一律全力運(yùn)轉(zhuǎn)。
你問它 “1+1 等于幾”,它把 1750 億個參數(shù)全拉出來遛一遍。你讓它寫篇博士論文,它也是用同樣的力氣。
就像一個大學(xué)教授,你問他幾點了,他也要從相對論開始講起。那有沒有辦法,讓 AI 學(xué)會 “看人下菜碟”?
有。
答案藏在一種你絕對想不到的生物身上。
小龍蝦教 AI 的事
這種生物就是 —— 小龍蝦。
別笑。小龍蝦的神經(jīng)系統(tǒng),是神經(jīng)科學(xué)界的 “教科書級” 研究對象。
它有一個讓所有 AI 工程師眼紅的特性:反應(yīng)極快,而且?guī)缀醪毁M電。
怎么做到的?
因為小龍蝦的腦子是分層的:
- 底層(反射弧):負(fù)責(zé) “逃!” 這種緊急任務(wù),速度快、不費腦
- 高層(大腦):負(fù)責(zé) “這玩意兒能吃嗎” 這種復(fù)雜問題,速度慢、費能量
大部分情況,底層就把活干了。高層大多數(shù)時間在 “摸魚”—— 低功耗待機(jī)。這就是小龍蝦用一丁點能量活得好好的秘密。
而我們的大模型,永遠(yuǎn)在用 “高層大腦” 處理一切。

把小龍蝦的 “分層大腦” 塞進(jìn) AI
2019 年前后,幾個研究團(tuán)隊同時想到了一個點子:
能不能給 AI 也裝一個 “反射弧”?
于是,一項叫 “早期退出機(jī)制” 的技術(shù)誕生了。原理不復(fù)雜:
在神經(jīng)網(wǎng)絡(luò)中間,開幾個 “側(cè)門”。
- 如果模型在前面幾層就已經(jīng)很有把握,就從 “側(cè)門” 直接輸出結(jié)果,后面的層根本不用跑
- 如果模型拿不準(zhǔn),才繼續(xù)往下走,動用全部算力仔細(xì)判斷
就像你做選擇題:
第一眼就知道選 A,直接寫答案,后面的選項看都不看
拿不準(zhǔn),才把四個選項都分析一遍結(jié)果準(zhǔn)確率幾乎不變,有時候反而更高。
這就是小龍蝦技術(shù)的核心原理:不是讓模型變 “笨”,而是讓它學(xué)會該用力時用力,該省電時省電。
“小龍蝦” 還能怎么進(jìn)化?
早期退出” 只是第一代。真正的小龍蝦技術(shù),還有更狠的玩法。
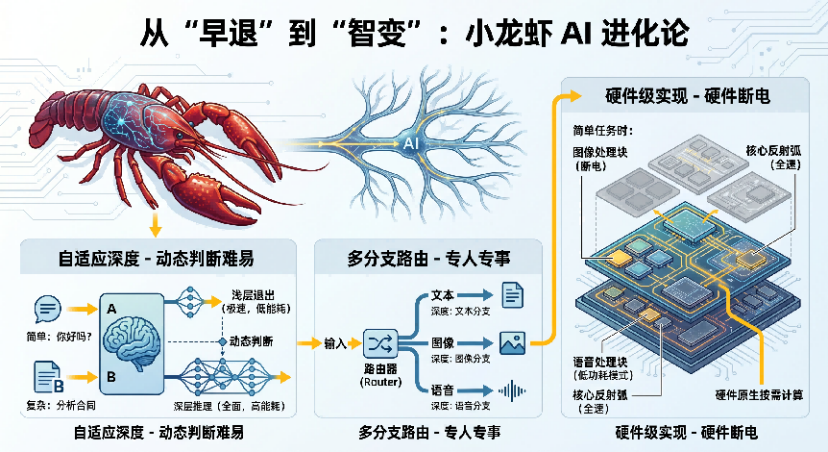
1. 自適應(yīng)深度(Adaptive Depth)
不固定在第幾層退出,而是根據(jù)輸入難度動態(tài)調(diào)整。
- “你好嗎” → 淺層退出
- 分析這份合同的風(fēng)險條款” → 深層推理
模型會自動判斷:這道題是 “1+1” 還是 “哥德巴赫猜想”。
2. 多分支路由(Multi-exit Routing)
不是一條直路,而是多個分支并行。
一個輸入進(jìn)來,先經(jīng)過一個 “路由器”。路由器判斷:這是圖像、文本還是語音?
- 圖像走圖像分支
- 文本走文本分支
每條的 “深度” 不一樣。就像醫(yī)院分診臺:感冒去普通門診,癌癥去專家號。
3. 硬件級實現(xiàn)(Hardware Support)
最炸裂的是:Intel、IBM 已經(jīng)在做芯片原生支持的小龍蝦。
不是軟件模擬,而是硬件層面就支持 “按需計算”—— 簡單任務(wù)時,某些電路層直接斷電。這才是真正的 “省電”。不是 “少用”,而是 “不用”。
現(xiàn)在的大模型競賽,大家都在比誰更大、誰參數(shù)更多、誰算力更強(qiáng)。
但 “小龍蝦” 告訴我們另一條路:
聰明的 AI,不是算得最多的那個,而是知道什么時候該算、什么時候可以不算的那個。
不是所有問題都需要全力解決。學(xué)會 “分層思考”,可能是更高級的智慧。畢竟 —— 連一只小龍蝦都懂這個道理。
